Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 74 The abridged build-measure-learn loop: innovate and seek excellence12-Feb-2013The principal objective of a tech startup (Research and Development also fit the shoes of tech entrepreneurship without loss of generality) is to learn how to build and run a sustainable business where value is created when a new technology invention is matched to customer need. Therefore, validated learning is a fundamental issue in this uncertain quest for success. Ideas are born of initial leaps of faith. But then, they need to be conceptualised, sketched, implemented, submitted for testing through a minimum viable product, and by making use of innovation accounting and actionable metrics, the results have to be evaluated and the decision must be made whether to pivot or persevere. It is true that simulation is useful to understand the impact of uncertainty on the distribution of expected outcomes, but the real world is much harder to debug than a piece of code and there is always the need to iterate a business idea with real people (i.e., prospect customers) in order to discover their actual needs. Similarly, in innovation management, it is said that the innovation that moves along the technology and market curves is incremental (persevere), in contrast to the innovation that is disruptive, which introduces a discontinuity and shifts to new curves (pivot). A pivot is a special kind of structured change designed to test a new fundamental hypothesis about the product, business model and engine of growth. It is the heart of the Lean Startup method (in fact, the runway of a startup is the number of pivots that it can do), which makes a company resilient in the face of failures (which are not mistakes, this is a different issue). However, there is (at least) one peril/caveat wrt the Lean Startup method (what's left out of the pivoting topic): if you do have true expertise in a particular field, you are then likely succeed and end up doing something of value for the customers you discovered, but this is no guarantee to be a rewarding experience to you. In that situation, you cannot do great work (unless you have a very wide band or changing taste, your work preferences will prevent you from doing a great job). We know from Steve Jobs that "the only way to do great work is to love what you do", so one might still need to pivot in that situation, too. Joel Spolsky also proclaims this message in his "careers badge": Love your job. Or else, pivot, and have a read at Cal Newport's book: So Good They Can't Ignore You, where it is supported that what you do for a living is much less important than how you do it, focusing on the hard work that is required to become excellent at something valuable instead of keeping pivoting until all variables fit your taste.
 In a recent podcast, though, Cal emphasises the importance of craftsmanship, which is somewhat contradictory because craftsmanship is rather associated with passion. Anyhow, it's a sensible link and it's always reasonable to bear in mind the reverse side of an argument. Post 73 A New Year's resolution: get over specialisation and embrace generalisation to face real world industry problems01-Jan-2013Regularisation is a recurrent issue in Machine Learning (and so it is in this blog, see this post). Prof. Hinton also borrowed the concept in his neural networked view of the world, and used a shocking term like "unlearning" to refer to it. Interesting as it sounds, to achieve a greater effectiveness, one must not learn the idiosyncrasies of the data, one must remain a little ignorant in order to discover the true behaviour of the data. In this post, I revisit typical weight penalties like Tikhonov (L-2 norm), Lasso (L-1 norm) and Student-t (sum of logs of squared weights), which function as model regularisers:
 And their representation in the feature space is shown as follows (the code is available here; this time I used the Nelder-Mead Simplex algorithm to fit the linear discriminant functions):
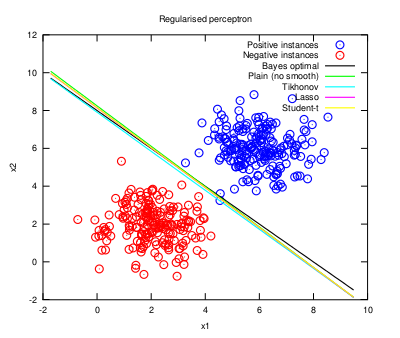 As expected, the regularised models generalise better because they approach the optimal solution, although the differences are small for the problem at hand. Even more different regularisation proposals could still be suggested using model ensembles through bagging, dropout, etc, but are they indeed necessary? Does one really need to bother learning them? The obtained results are more or less the same, anyway. What is more, not every situation may come down to optimising a model with a fancy smoothing method. For example, you can refer to a discussion about product improvement in Eric Ries' "The Lean Startup" book (page 126, Optimisation Versus Learning), where optimising under great uncertainty can lead to a total useless product in addition to a big waste of time and effort (as the true objective function, i.e., the success indicator the product needs to become great, is unknown). And still further, not in the startup scenario but in a more established industry like the rail transport, David Briginshaw (Editor-in-Chief of the International Railway Journal, October 2012) wrote: "Specialisation leads to people becoming blinkered with a very narrow view of their small field of activity, which is bad for their career development, (...), and can hamper their ability to make good judgements." So, a lack of generalisation (as in happens with overfitted models) leads to a useless skewed vision of the world. Abraham Maslow already put it in different words: if you only have a hammer, you tend to see every problem as a nail. This reflection inevitably puts into scene the people who are at the crest of specialisation: the PhD's. Is there any place for them outside the fancy world of academia where they usually dwell and solve imaginary problems? Are they ready to face the real tangible problems (which are not only technical) commonly found in the industry? The world is harder to debug than any snippet of fancy code. Daniel Lemire long discussed these aspects and stated that training more PhD's in some targeted areas might fail to improve research output in these areas. Instead, creating new research jobs would be a preferable choice, as it is usually the case that academic papers do not suit many engineering needs and those fancy (reportedly enhanced) methods are thus never adopted by the industry. His articles are worth a read. Research is indeed necessary to solve real world problems, but it must be led by added-value objectives, lest it be of no use at all. Free happy-go-lucky research should not be a choice nowadays (has anyone heard of the financial abyss in academia?). Post 72 Sure, you can do that... and still get an IEEE published article24-Dec-2012This year has been rather prolific with respect to the attained number of research publications. The most noteworthy is the one on the IEEE Transactions on Audio, Speech and Language Processing (TASLP), which is entitled "Sentence-based Sentiment Analysis for Expressive Text-to-Speech". Its abstract is posted as follows: "Current research to improve state of the art Text-To- Speech (TTS) synthesis studies both the processing of input text and the ability to render natural expressive speech. Focusing on the former as a front-end task in the production of synthetic speech, this article investigates the proper adaptation of a Sentiment Analysis procedure (positive/neutral/negative) that can then be used as an input feature for expressive speech synthesis. To this end, we evaluate different combinations of textual features and classifiers to determine the most appropriate adaptation procedure. The effectiveness of this scheme for Sentiment Analysis is evaluated using the Semeval 2007 dataset and a Twitter corpus, for their affective nature and their granularity at the sentence level, which is appropriate for an expressive TTS scenario. The experiments conducted validate the proposed procedure with respect to the state of the art for Sentiment Analysis." In addition, three other publications at the SEPLN 2012 Conference (see Publications) have allowed focusing on specific aspects as subsets of a greater whole (i.e., the IEEE TASLP article). This has been hard work, indeed. And I'm proud of it. Nonetheless, I cannot help being objective about it and admit that this line of research falls into the "data porn" category (check out the "publication Markov Chain" that is being mocked there). In any case, the addressed problem is a real one and alternative sources of knowledge have been considered to solve it, so this an altogether good lesson learnt. By the way, Merry Xmas! Post 71 Perceptron learning with the overused Least Squares method02-Nov-2012Following Geoffrey Hinton's lectures on Neural Networks for Machine Learning, this post overviews the Perceptron, a single-layer artificial neural network that provides a lot of learning power, especially by tuning the strategy that is used for training the weights (note that Support Vector Machines are Perceptrons in the end). To keep things simple, 1) no regularisation issues will be covered here, and 2) the weight optimisation criterion will be the minimisation of the squared error cost function, which can be happily overused. In another post, the similarity between using the least squares method and the cross-entropy cost through the negative log-likelihood function (as it is reviewed in class) assuming a Gaussian error was already discussed. So using one or the other won't yield much effectiveness improvement for a classic toy dataset sampled from two Gaussian distributions. Therefore, the ability of the perceptron to excel in classification tasks effectively relies on its activation function. In the lectures, the following functions are reviewed: binary, linear, logit and softmax. All of them provide their own singular learning capability, but the nature of the data for the problem at hand is always a determining factor to consider. The binary activation function is mainly used for describing the Perceptron rule, which updates the weights according to the steepest descent. Although this method is usually presented as an isolated golden rule, not linked with the gradient, the math is clearer than the wording:
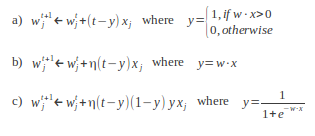 The gradient for the logit is appended in the figure above to see how a different activation function (and thus a different cost function to minimise) provides an equivalent discriminant function (note that the softmax is a generalisation of the logit to multiple categories, so it makes little sense here):
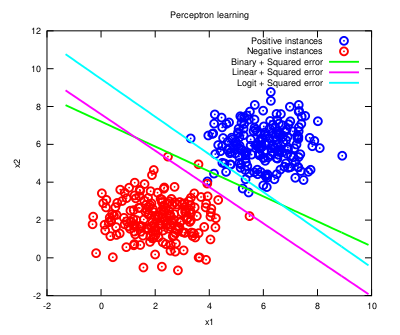 As it can be observed in the plot, the form of the activation indeed shapes the decision function under the same cost criterion (not of much use here, though). In certain situations, this can make the difference between a good model and an astounding one. Note that different optimisation functions require different learning rates to reach convergence (you may check the code here). And this process can be further studied with many different activation functions (have a look at the variety of sigmoids that is available) as long as the cost function is well conformed (i.e., it is a convex function). Just for the record, the Perceptron as we know it is attributed to Rosenblatt, but similar discussions can be found with respect to the Adaline model, by Widrow and Hoff. Don't let fancy scientific digressions disguise such a useful machine learning model! Post 70 Least Squares regression with outliers is tricky23-Jul-2012If reams of disorganised data is all you can see around you, a Least Squares regression may be a sensible tool to make some sense out of them (or at least to approximate them within a reasonable interval, making the analysis problem more tractable). Fitting functions to data is a pervasive issue in many aspects of data engineering. But since the devil is in the details, different objective criteria may cause the optimisation results to diverge considerably (especially if outliers are present), misleading the interpretation of the study, so this aspect cannot be taken carelessly. For the sake of simplicity, linear regression is considered in this post. In the following lines, Ordinary Least Squares (OLS), aka Linear Least Squares, Total Least Squares (TLS) and Iteratively Reweighted Least Squares (IRWLS) are discussed to accurately regress some points following a linear function, but with an outlying nuisance, to evaluate the ability of each method to succeed against such a noisy instance (this is fairly usual in a real-world setting). OLS is the most common and naive method to regress data. It is based on the minimisation of a squared distance objective function, which is the vertical residual between the measured values and their corresponding current predicted values. In some problems, though, instead of having measurement errors along one particular axis, the measured points have uncertainty in all directions, which is known as the errors-in-variables model. In this case, using TLS with mean subtraction (beware of heteroskedastic settings, which seem quite likely to appear with outliers; otherwise the process is not statistically optimal) could be a better choice because it minimises the sum of orthogonal squared distances to the regression line. Finally, IRWLS with a bisquare weighting function is regarded as a robust regression method to mitigate the influence of outliers, linking with M-estimation in robust statistics. The results are shown as follows:
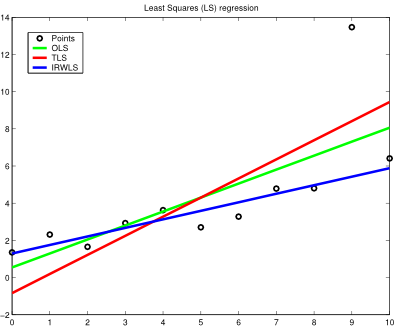 According to the shown results, OLS and TLS (with mean subtraction) display a similar behaviour despite their differing optimisation criteria, which is slightly affected by the outlier (TLS is more affected than OLS). Instead, IRWLS with a bisquare weighting function maintains the overall spirit of the data distribution and pays little attention to the skewed information provided by the outlier. So, next time reliable regression results are needed, the bare bones of the regression method of use are of mandatory consideration. Note: I used Matlab for this experiment (the code is available here). I still do support the use of open-source tools for educational purposes, as it is a most enriching experience to discover (and master) the traits and flaws of OSS and proprietary numerical computing platforms, but for once, I followed Joel Spolsky's 9th principle to better code: use the best tools money can buy. Post 69 On using Hacker News to validate a product idea involving NLP and PHP12-Jul-2012The first step to creating a valuable product is to discover what it is exactly wanted or needed by the target customers. The Lean Startup process states it straight, and the Pragmatic Programmer even provides a means to find it out by asking Hacker News (HN). HN is a vibrant community of tech people, hackers is its broadest sense... and entrepreneurs (these concepts need not be disjoint), which can provide a lot of insight into the value of a product idea. Now, my product idea: a general-purpose Natural Language Processing (NLP) toolkit coded in PHP. This is certainly a long wanted product (note that the two links date back to 2008), and for a sensible reason: the Internet is bloated with textual content, so let's develop a NLP tool that is focused on processing text on the web. In this sense, the PHP programming language, i.e., by definition, the Hypertext Preprocessor, should be a practical choice with which to do it. Moreover, PHP is the default platform that is available on a web server. Then, all the elements seem to be in the right place. And the problem seems to be addressed logically this way, but it still needs positive feedback from the end users (the developers) to succeed. Note that none of the currently available NLP toolkits reported in the Wikipedia list has been developed in PHP, so there must be a niche of improvement here, or must there be something wrong going on? Why is it so? Perhaps the product was not interesting a few years ago, maybe it did not catch up because of marketing issues, or using the many bindings and wrappers available was just enough in contrast to putting the effort in doing it all again from scratch... Therefore, the question naturally arises: is it really interesting to the community? If so, to what extent? Is it worth the bother? Will this be a profitable project? Would it be nuts to rely solely on Ian Barber's opinion? These questions require some scientific experimentation, so I built a prototype (mainly based on text classification, which has 24 GitHub watchers at this time of writing; thanks for your interest, indeed) and submitted it to HN. What I found out was contrary to what I expected: the general interest in this kind of product is essentially nonexistent, just in line with what had already happened with the previous approaches. I failed. OK. At least I now know by myself it's nonsense to invest in this product. I'd better do something else. Fine. Let's keep engineering. The upside is that I practised some PHP (my skills with this language were getting a little rusty) and (more importantly) I learnt that businesses need solutions, not tools to develop solutions (this conclusion is derived directly from the only -ironic- comment that appears in HN, which was motivated by the demo app that I provided where I trained the classifier with a popular research dataset only as a proof of concept). That's awesome! If I had dismissed the so-valuable Lean Startup directive, assuming that the world was just how I saw it, I would have "wasted" (please note the quotation marks) a whole lot of time developing something nobody would pay for (I'm being rather like Edison here, I know). This is an undoubtedly good "lesson learned". Needless to say, though, if I ever get to obtain economic support for its development, I will gladly resume the coding phase! Post 68 The Passionate Programmer in the late-2000s recession03-Jun-2012The present receding economy displays a scenario that is wildly unknown, and this inevitably affects the attitude that we take with respect to our careers, reminding us all of the crucial importance to always be heading to where the magic happens. In addition to the renown advice to not settle, what's utterly of value is to stay hungry in this continuously changing world. In this regard, the Passionate (and Pragmatic) Programmer provides some insight that is worth noting. In this post, I review some of its guidelines to "create a remarkable career in software development", and the many connections with the present situation arise naturally (the book was published three years ago):
 And last but not least: you can't creatively help a business until you know how it works. In this regard, the next book in my reading list is The Lean Startup. Post 67 Numerical computation platform for the technical university: values to decide on a proprietary or open-source software model30-Mar-2012A discussion on the adequacy of a proprietary numerical computation platform like Matlab or a free open source alternative like Octave is an old story already. But I feel it would be inadequate to stick with rigid values only because of one's preference for a single particular software development model. To me, one is just as good as the other. And I opine with certain authority being a TA at the university who led the migration from Matlab to Scilab for the practise sessions of Discrete-Time Signal Processing (a graphical interface for simulating dynamic systems was required, therefore xcos was needed), which is part of the Master's degree programme in Telecommunications Engineering. Needless to say, I have a preference for open-source software, but in an educational environment such as the university, choosing an open platform for teaching is more of an act of responsibility than it is of taste. Here are the reasons why I bothered remaking from scratch the whole lot of practise sessions (see my teaching materials) with Scilab:
With these arguments I don't mean that Matlab is a bad product at all in any sense! On the contrary, as long as people acquire it, I assume it must provide some differentiated solutions for specific needs. But in an university environment, where the gist of a technical class is teaching off-the-shelf methods to fledgling engineers, open-source software packages like Octave, Scilab or SciPy, offer high quality numerical computation platforms that are orders of magnitude more powerful than it is needed. What is more, I have used them myself for more serious computing tasks, and in my experience, strictly speaking, they are truly comparable to their proprietary counterparts. Now, while this seems to be a reasonable an sound argument (IMHO), related companies seem to disagree and complain to the university to prevent the publication of such opinions and to remove the teaching materials that we instructors offer for free for the sake of education. If such complaints are not simply dismissed as the university is supposed to always protect the educational freedom, students are in threat of being tangled with the monopoly dictated by these companies (and shamefully accepted by the university). So this is what happened to Guillem Borrell with Mathworks and the Universidad Politecnica de Madrid. And since I share his indignation wrt this issue, I wanted to echo his open letter to Mathworks. I wonder if this company will also complain to Andrew Ng for the similar opinions he expressed in the materials he prepared for the Machine Learning class. Post 66 Spelling correction and the death of words23-Mar-2012One of the topics treated in this second week of the Natural Language Processing class at Coursera is spelling correction (also treated in the Artificial Intelligence class). It's wonderful to have tools that help proofreading manuscripts, but this comes at the expense of impoverishing our own expression ability. This newspaper article, which links to the original research work conducted by Alexander Petersen, Joel Tenenbaum, Shlomo Havlin and Eugene Stanley, states that spelling correction (not only computerised but also human-made in the editorial industry) causes language to be homogenised, and this eventually reduces the lexicon (old words die at a faster rate than new words are created). So, is this NLP fancy topic actually hurting NLP? What a headache... Anyway, I find this spelling correction field very appealing because it shows a direct link with speech (i.e., spoken language) through the consideration of a phonetic criterion in the spelling error model. This points to the metaphone algorithm, which creates the same key for similar sounding words. It is reported that metaphone is more accurate than soundex as it knows the basic rules of English pronunciation. Regarding spelling correction, metaphone is used in GNU Aspell, and to my surprise, it's already integrated in the latest versions of PHP! Along with the edit distance topic treated in the first week, this shall make a new addition (e.g., a phonetic similarity module) to the NLP toolkit I'm beginning to work on! Post 65 Hacking with Multinomial Naive Bayes29-Feb-2012Today it's the most significant day of a leap year, and I won't miss the chance to blog a little. I think I can put Udacity aside for a moment to note the importance of Naive Bayes in the hacker world. Regardless of its naive assumption of feature independence, which does not hold for text data due to the grammatical structure of language, the classification decisions (based on Bayes decision rule) of this oversimplified model are surprisingly good. I am particularly fond of implementing the Multinomial version of Naive Bayes as is defined in (Manning, et al., 2008), and I must say that for certain problems (namely for sentiment analysis) it improves the state-of-the-art baseline straightaway. My open source implementation is available here, as well as a couple of example applications on sentiment analysis and topic detection. UPDATE on 07-Mar-2012: A book entitled "Machine Learning for Hackers" has just been published.
-- newer | older - RSS - Search |
All contents © Alexandre Trilla 2008-2025 |
{kind=link}
{kind=link}