Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 54 VIm, 20 years old04-Nov-2011
I would like to cite the 22nd pragmatic programming tip (Hunt and Thomas,
1999), which says: Although VIm was originally designed as a VI clone for the Amiga, it was soon ported to other platforms and eventually grew to become the most popular VI-compatible text editor. If you want to take a brief look back at the history of VI and explore some of the compelling technical features that continue to make VIm relevant today, read this article.
-- Post 53 Natural Language Generator (NLG) released01-Nov-2011I recall the tutorial that Noah Smith gave at LxMLS about Sequence Models with much interest. Motivated and inspired by his explanation, today I release a Natural Language Generator (NLG) based on n-gram Language Models (see the CODE section). Under the generative modelling paradigm, the history-based model P(w_n|w_1,w_2,...,w_{n-1}) (see further analysis in the NLG docs) may be graphically represented by a finite-state machine/automaton such as the Co-Occurrence Network (Mihalcea and Radev, 2011) that appears in Alias, et al. (2008), see the figure below. I find it self explanatory (a picture is worth a thousand words; it's funny to put it this way from a language processing perspective). Although it is limited by its first-order history (the NLG rather generalises its topology), the tutorial did not show such a clear representation of the model.
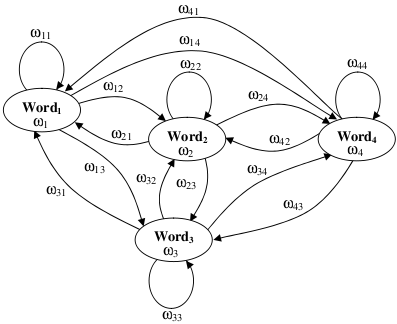 I especially enjoyed the complexity issues that were raised regarding the length of the considered history (i.e., the order of the Markov model): from the Bag-Of-Words (BOW) model with few parameters and strong independence assumptions to the infinite-history-based model with a rich expressive power to represent language. Prof. Smith conducted an example experiment where he used a corpus of 2.8M words of American political blog text to display how this expressive power can learn and generate natural language. First, he showed how a unigram model (i.e., a BOW) could not produce anything that made any sense. Second, he showed how a bigram model could only produce a few phrases with sense. The experiment went on up to a 100-gram language model, which just copied text straight from training instances. Imagine how the aforementioned graphical network would look like in these scenarios, from a fully connected network of words (i.e., unigrams) to a mesh of higher order grams. He ended up discussing that in the past few years, "webscale" n-gram models have become very popular because it's very hard to beat them. In this post I reproduce the experiment with the NLG using "The Legend Of Sleepy Hollow", by Washington Irving, thanks to the e-book provided by Project Gutenberg (I could not find a more appropriate book after Halloween). What follows are some of the generated outputs:
Unigram model
Bigram model
Trigram model
5-gram model As it can be observed, as the model gains expressive power by means of its increased order, it can generate more quality natural language instances. Finally, as it is customary, the source code organisation of the NLG follows common FLOSS directives (such as src folder, doc, README, HACKING, COPYING, etc.). It only depends externally on the Boost Iostreams Library for tokenising text, and it makes use of the premake build script generation tool. I hope you enjoy it.
-- Post 52 Logistic Regression in Machine Learning30-Oct-2011This week's work in the Stanford ml-class has covered Logistic Regression (LR) and Regularisation in regression models (both linear and logistic). I do believe Prof. Ng when he states that LR is the most widely used classification method in the world. A well-designed LR strategy is determined to pass any test with flying colours, hence its renown effectiveness. LR is full of wonders, most of which are grasped in the lecture, but I would still like to review a few aspects that I think deserve a deeper analysis. First of all, I find that the philosophy of learning of the LR is of most interest, and this is quite skimmed over in the lecture. Its discriminative strategy modelling the boundaries among the classes is shown, but maybe the contrast with its counterpart generative strategies (such as Naive Bayes) would have made it more understandable, like the classification lecture that Prof. Crammer gave at LxMLS. I'm keen on seeing the reverse of the coin (or some reasonable alternative) when learning (and teaching) something. In other research fields such as Natural Language Processing, LR is renamed to Maximum Entropy, supporting that the distribution of the learnt model is as uniform as possible (hence with maximum entropy) given that it does not assume anything beyond what is directly observed in the training data. Moreover, I have also found lacking the notice of its origin, which intended to symmetrically model the odds-ratio of a prediction, see this. With regard to the multiclass generalisation with the One-Versus-All strategy (as if it only was a dichotomic classifier like a Support Vector Machine, coming soon), I particularly missed the Multinomial distribution, which naturally integrates this multiclass requirement. In addition, it gives birth to the so called Multinomial Logistic Regression, generally used in Computational Linguistics software suites like LingPipe. What is more, their implementation is based on the Stochastic Gradient Descent algorithm (Carpenter, 2008), which is a randomised online interpretation of the classical gradient descent algorithm shown at ml-class. One thing I've enjoyed is the tackling of complex problems with LR. By complex I mean needing a hypothesis function more sophisticated than a typical linear discriminant. The fun has been in discovering the need of regularisation to prevent overfitting with such a new complex function (which comes at a price). And perhaps I would even have delved beyond the Tikhonov regularisation to unearth other methods like the Ridge Regression and the Lasso, i.e., LR with Gaussian and Laplace priors on the parameters, respectively. Finally, to see the behaviour of LR wrt the ideal boundary, let's follow what was done in the LxMLS lab for classification, see this guide. Let's conduct a very controlled and simple experiment with two equally sized instance groups coming from normal distributions representing the two classes. Since the true joint distributions P(X,Y) that generate the data are thus known, the Bayes Optimal decision boundary can be analytically calculated (Duda, et al., 2001). The simplest case occurs when the features are statistically independent and each feature has the same variance. Geometrically, this corresponds to the situation in which the instances fall in equal-size hyperspherical clusters, and the boundary hyperplane is the perpendicular bisector of the line linking the means of the clusters. The figure below shows the Bayes Optimal and the Decision Boundary obtained with LR superimposed on the scatter plot of the data instances. As it can be observed, LR is very close to the optimum boundary. Depending on the distributions that generate the data (usually unknown), these boundaries may differ more or less, but LR equally yields a highly effective solution.
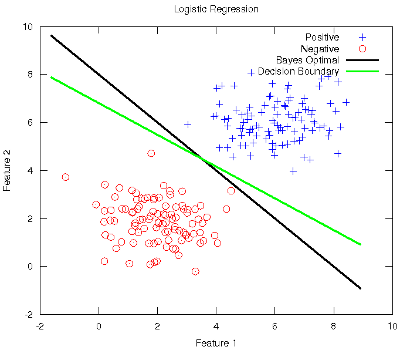 The Octave code used to generate the figure is available here. Note that the rest of the ml-class files need be present along with the former.
-- Post 51 Linear regression in Machine Learning16-Oct-2011Today is the deadline for submitting the first Review Questions of Stanford's Machine Learning course, which regard Linear Regression (LR) with one variable and Linear Algebra. I enrolled late this week and my experience with it has been very exciting. Andrew Ng has an outstanding ability to teach, and the lectures are most understandable with the digital board. But I'm a bit confused wrt the intended audience, because the gradient descent algorithm is presented along with the basic matrix operations (in a sense, the former is taught at 4th year of engineering while the latter at 1st year). Anyhow, the course seems great. Nevertheless, maybe I would prefer presenting certain topics as natural evolutions of evident problems, and provide alternative ways to solve a particular problem in order to avoid method idealisms. For example, after the LR problem is presented as an optimisation problem with respect to half the Mean Squared Error criterion, I would emphasise the general form of this cost function to ease the transition to other methods (e.g., the negative corpus log-likelihood for the Logistic Regression, to come on October 24th - 30th). Then, the solution of this optimisation problem could first be set in closed-form (by solving the null derivative equation). But in face of its apparent difficulty, numeric methods would then be well regarded. In this sense, the Gradient Descent (GD) is one possible solution, but others like the Nelder-Mead method or Genetic Algorithms could also work well. Finally, the batch GD algorithm is noted as a pitfall for speed, discussing a fancy learning rate and skimming over the stopping criterion. Hence, online GD algorithms like the sequentiality assumption of the Least Mean Square rule (aka Widrow-Hoff rule) or the random learning pattern of the Stochastic GD could be of help here. Although they sometimes lack a bit of accuracy because of the single-sample approximation (see the figure below), their use is a must for real-time processing environments.
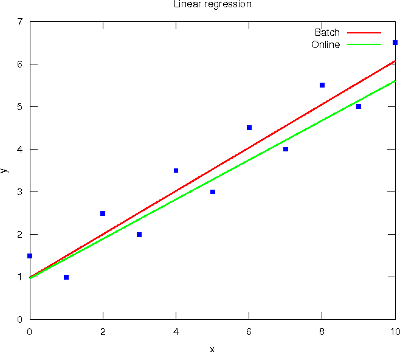 The Octave code used to generate the above regressions is available here for the batch version, and here for the online version. Post 50 Hyper{space,plane}08-Oct-2011
 (Click here to enlarge) Star Wars, Machine Learning and Linux: an Eternal Golden Braid (and yes, I'm also fond of Douglas R. Hofstadter's book). I guess I just wondered how Randall Munroe (xkcd), Jorge Cham (PhD Comics) or Scott Adams (Dilbert) felt like after publishing one of their terrific comic strips. I did by best. Post 49 LxMLS retrospective28-Jul-2011The 1st Lisbon Machine Learning School LxMLS was warmly received and ended this week in complete success. The summer school has had many engaging qualities, not the least of which has been its magnificent set-up, just check out its schedule. Over 200+ applications, 130 candidates, most of whom were PhD students, enjoyed such a comprehensive program oriented to statistical natural language processing. All the materials, including the slides, lab docs and code (in Python), are available at L2F. Although the banner of the school shows a skew toward the web, I guess it's only a matter of adding a little NLTK clean_html to be just right :-) Post 48 Textual media is missed in multimedia15-Jul-2011This week, La Salle has hosted the IEEE International Conference on Multimedia and Expo (ICME 2011). As a volunteer I can state that it has been a great experience being involved in its development. Especially if one is somewhat interested in image and audio processing. Nevertheless, one thing I generally miss in multimedia is its dismissal of the textual media. Despite the insistent reference to text in other fields when regarding multimedia (such as Dan Schonfeld and Li Deng, guest editors of the IEEE Signal Processing Magazine, vol. 28, n. 4, July 2011), there have been very few accepted works in the conference that have considered some textual issue. Although text is well available from images (OCR) as well as from speech (transcription via ASR), it is often ignored as a value-added feature. I even seldom hear that text is becoming sort of old-fashioned among the trendy media. But IMO, some of the most difficult problems in human interaction still stem in the machine comprehension of natural language (see The Loebner Prize in Artificial Intelligence), and until an acceptable rate may be achieved in this regard, text and hence Natural Language Processing are determined to be present in original research. This is my silly rant about the conference, which I deeply regret because overall it has been tremendous. Post 47 X JPL06-Jul-2011Past Friday, July the 1st, I could enjoy the last day of the 10th Free Software Symposium (Jornades de Programari Lliure, JPL, in Catalan), which was held at UPC, Barcelona. In the morning, Prof. Arcadi Oliveres and Prof. Joan Tugores gave an overview of the economic and social impact of new technologies, trying to establish links with the free and proprietary software models. Prof. Oliveres overtly discussed that the lack of information that arrives from the non-independent mass media makes people live a lie. In the same line, Prof. Tugores generalised that the more uneven is a society, the fewer are the business/economic groups that share the power to make (big scale) decisions, and the more easily influenced they are to private (and sometimes dishonest) interests. That reminded me of the Builderberg Group altogether, and Uncle Ben with the often-quoted Spider-Man theme of "with great power comes great responsibility". A debate followed to discuss the social, economic and political impact of free software. Among the many interesting topics that were treated, it surprised me an analogy of the Anonymous' deeds with a former hacker group named CCC (I didn't jot down what the acronym stands for, though), which revealed some sensitive information that the USSR had hidden and prevented the 4 reactors of the Chernobyl nuclear plant from beginning a fusion chain reaction. God bless those hackers! Similarly, the speakers raised the interest of monopolies in the spreading of software piracy, which is used as a "drug" to retain users. There was also a reference to some study that shows that piracy actually does not harm authors. So what's the fuss about piracy in the end? By the way, the SGAE has just been prosecuted for embezzlement of funds (see this and this). In the afternoon, a series of technical presentations followed. Pere Urbon introduced NoSQL, which are unstructured DBMSs that relax the ACID properties. He pointed out their ability to scale horizontally and their ease of replicability and distribution, at the expense of weaker consistency. Next, Albert Astols presented the modus operandi of the KDE translator community, with all the details about the .pot files and their management. Marc Palol followed with cloud computing as the future new paradigm of FLOSS communities. He centred his speech around Hadoop (the free implementation of Google's MapReduce) as an example of distributed computing platform. Finally, Israel Ferrer talked about the greatnesses of Android wrt former mobile platforms like JavaME, but admitted its excessive fragmentation with so many official releases and the device manufacturer's own refinements. I did find the Intents (abstract descriptions of operations to be performed) ability very ingenious, though. Post 46 Robotics at La Salle with Prof. Chris Rogers28-Jun-2011Professor Chris Rogers, from Tufts University, gave a speech promoting creativity and innovation with pre-college engineering education, a kind of mirror talk wrt his probably more renown Talk at Google entitled "LEGO Engineering: From Kindergarten to College". Although I've traditionally been more keen on using Meccano (it's more heavy metal), I must admit that LEGO is astonishing (it's lighter and it doesn't oxidise), especially regarding the more "technical track" available with the use of the NXT microcontroller. Truly enticing. Prof. Rogers makes use of robotics (as an integrating engineering field) to teach a wide range of students considering the level of their school science subjects. Indeed, a Segway built out of LEGO pieces is a remarkable feat of engineering by itself, with all the control theory underneath. And this might even go further, say, if pneumatics had a role in the play (despite not being considered in his speech, they are also available from LEGO, with the compressors, pistons, valves and so on). Surely we all remember studying the Industrial Revolution through the steam engine. So it's like those beautiful Stuart Models (long live steampunk), in plastic, and with electronic control to play with. It's amazing. Definitely, microbotics is the new (geek) hobby of the 21st century. And always bear in mind that a Tux Droid never dies! Post 45 Free software needs free speech07-Apr-2011I just wanted to echo this recent encouraging post to contribute to speech-related free software apps. It discusses the benefits of contributing to such FLOSS applications, which not only need good coders, but also big amounts of recorded speech data to train the acoustic models. The recordings requested a while ago (see Post 36) for Spanish are still being processed and no results are yet available. newer | older - RSS - Search |
All contents © Alexandre Trilla 2008-2025 |
{kind=link}