Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 44 Pipeline Skeleton released02-Feb-2011Regarding Bob Carpenter's ready-to-distribute pyhi package, a bare bones Python package with all the trimmings (modular structure, configurability, building automation, etc.), and his apparent latter skew to C/C++, I thought it would be interesting and useful to have a similar package in C++. Such framework could be based on a sequential processing structure, which modules could be defined (and redefined) in an external XML config file, and its core implementation could be abstract with regard to concrete application needs (declaring pure virtual functions), thus defining a neat interface ready to be extended for any particular purpose. So, I've just released the Pipeline Skeleton (see the CODE section of my homepage). The Pipeline Skeleton intends to provide an adequate ground framework to buttress a (e.g. spoken language processing) data processing project without compromising its future growth. The main motivation for coding it responds to Bjarne Stroustrup's claim (for example) that "modularity is a fundamental aspect of all successful large programs". The point is to avoid throwing away (and redoing from scratch) pieces of code produced a while ago because their original design did not consider any extensibility and/or reusability aspects. Maintaining such an awful code is a waste of time eventually, not to mention the problems that arise if many programmers work on the same project code, it's a headache altogether. Every time a critical variable is hardcoded, a piece of code is left undocumented, or the like, the future of a program is jeopardised and sooner or later its developers will have to face these bad coding practices, unless the program in question dies prematurely an nobody ever needs to run it again. Unfortunately, this is the acknowledged style of scientific code (see this and this) and we have to deal with it. Why C++? Because of performance issues, mainly. Java (to name a most comparable an extensively used OOP language, raising an eternal question) does perform swiftly with a JIT compiler under certain circumstances. But when a real-time response is required or pursued, dealing with large/huge amounts of data (e.g., a Wikipedia dump or a several-hours long speech corpus), Java does not yet seem to yield a comparable effectiveness wrt a natively compiled language like C++. C++ has always been meant for high performance applications. In the end, powerful virtual machines like OpenJDK's HotSpot and LLVM are written in C/C++. Why a sequential processing structure? Because many speech and language processing applications rely on some sort of pipeline architecture, e.g., see the Shinx-4 FrontEnd, which inspired the modular processing framework of the EmoLib Affective Tagger. Nevertheless, there is a design (and thus also implementation) difference between these examples and the Pipeline Skeleton. The former leave the data flow control to the processors (i.e. the modules), as they are arranged in a linked-list. The latter, instead, builds an array containing all the processors and iterates over them to process the data. This decision is motivated by code simplicity (and the Occam's Razor), given that the arrangement of processors is set in the XML config file and maintained throughout the processing session (at least this is the modus operandi that I have always followed to organise and conduct my experiments). Since no typical insertion an removal of processors is allowed after the pipeline initialisation step, there is no apparent need to keep the linked-list structure (anyway, the std::vector class also allows such operations). There is though some overhead introduced by the iteration loop (in addition to the common N dereferences and N function calls for N processors), but Stroustrup (1999) demonstrates that the reduction in code complexity can be obtained without loss of efficiency using the standard library. Finally, the "cyclic" class hierarchy in the FrontEnd where the pipeline extends the processor and also contains processors is reorganised into a tree-like hierarchy for conceptual clarity. The source code organisation of the Pipeline Skeleton follows common FLOSS directives (such as src folder, config, doc, README, HACKING, COPYING, etc.). It only depends externally on the TinyXML++ ticpp library for parsing XML files, and likewise it makes use of the premake build script generation tool. I hope you enjoy it.
-- Post 43 Full-text search ability in the blog posts21-Dec-2010As the number of posts in the blog increases from time to time, I have thought it would be a good idea to enable a full-text search option there. Hence, thematic posts regarding a search query may be retrieved within a few moments. In order to deploy such a text search engine, I have taken Ian Barber's Vector Space Model (VSM) implementation (in PHP) as reference. This (simple) search method first performs a free vocabulary indexing with the post texts directly, without applying any stopword filtering, stemming or lemmatisation procedures. Then it weights the terms with the tf-idf method so as to consider the local contribution of a term (post-wise) as well as its discriminating power within the collection (blog-wise). Finally, the most similar posts are retrieved and delivered to the user via a distributional similarity measure (a pseudo-cosine distance computed as the average sum of term weighted measures). Post 42 Information Retrieval techniques in ASR28-Nov-2010I also wanted to blog about Dr. Alex Acero's speech in the FALA 2010 conference. His talk was entitled "New Machine Learning approaches to Speech Recognition", and in brief (quoting his own description), he described some new approaches to Automatic Speech Recognition (ASR) that leverage large amounts of data using techniques from Information Retrieval (IR) and Machine Learning.
The "large amounts of data" detail of the description was in fact the gist of
his work. He recalled that Hidden Markov Model based ASR in the late 60's and
early 70's needed to compress a lot the acoustic features because otherwise
they could not succeed, due to computation capabilities. But today,
some of those assumptions may be challenged. In this regard, he presented
a novel ASR approach where the linguistic models were replaced by an IR
engine based on a Vector Space Model (VSM): 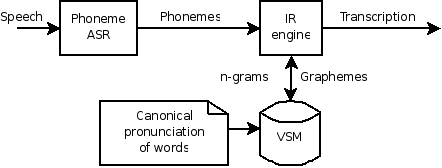 Dr. Acero conjectured that this approach works well if sufficient repetitions per word are available. Hence, by dealing with a huge amount of information, the system is supposed to deliver to a good performance, with an argued robustness to deal with disfluencies. Nevertheless, this novel approach (1) does not still solve the problems with homophony, and (2) gets confused with phoneme/syllable permutations. On the one hand, the classic indetermination with homophones persists at the phrase-level (e.g. the mondegreens) but also at the word-level (have some fun testing an ASR system with a list of words with similar Soundex indexes). On the other hand, the approach is weak toward disambiguating words with rearranged phonemes, e.g., "stop" and "spot" (regarding phonotactic rules in the rearrangement). And I know I'm being fussy here, because in a limited-domain scenario, this approach has actually yielded excellent results. So, although the linguistic knowledge of a speech-enabled application like ASR may not be directly replaceable in general, I find it is a most interesting work to approach different scientific disciplines, avoiding the idealisation of some particular method. Post 41 TTS in the future21-Nov-2010In the FALA 2010 conference, Dr. Heiga Zen gave a speech entitled "Fundamentals and recent advances in HMM-based speech synthesis". He reviewed the growth of Hidden Markov Models (HMM) over the last years in the TTS research community. Indeed, this direction was also evident in the Speech Synthesis Albayzin 2010 Evaluation, where out of the 10 systems participating, 3 were purely concatenative, 6 were based on HMM, and one was as a hybrid approach (HMM-based + concatenative). And it was the latter who won the competition. By the middle of his presentation, he cited Dr. Simon King's speech at the Interspeech 2010 conference stating that TTS synthesis is easy as long as some recommendations are followed. Overall, they suggest to avoid non-professional speakers, to avoid working with small corpora, with noisy recordings and labelling mistakes, and to acquire a deal of knowledge of the language aimed by the system. A core problem redefinition for research to tackle. Lastly, Dr. Zen encouraged the audience to join the research in TTS synthesis, and he provided some directions to get involved, beginning with text processing, i.e. the first stage in a TTS synthesis system. Thus, it seems that there is an especially nice and promising framework for my Ph.D. :) Post 40 FALA2010 contributions released10-Nov-2010Today the FALA2010 conference has begun, and our pending papers are now available in the publications section. NLP has been regarded to be one of the most attractive fields in TTS research nowadays, at least according to Heiga Zen, who has given a tutorial session on HMM-TTS synthesis this morning. I hope to report it asap. Moreover, we have presented our group paper highlighting Lluis Formiga's thesis on perceptual weight tuning in a unit selection process. This procedure has been applied to the present Albayzin competition, leading to significantly better MOS results wrt a plain implementation (a multilinear regression between the costs and the unit acoustic distances). Post 39 Reasons for students to contribute to Open Source04-Oct-2010I just wanted to echo Shalin's arguments to contribute to Open Source. In brief, Shalin supports having the chance to work on what one really likes, how beneficial this is for learning tools to face "real world" software problems (non-existent in academic problems), the experience gained from working with some of the best coders, and the attractiveness to companies that this profile yields. His original post can be found here. I do encourage students to enrol in open source projects for their Bachelor and Master's Thesis Projects. In the end, it is most probable that they get to use some open source tools to supply particular parts, and concentrate on their academic interests. So, why not contribute? Post 38 Discrete-Time Signal Processing with Scilab16-Sep-2010For years, Matlab has been has been the de facto choice for many tasks at the university, including teaching. While it is reputed to be a technically fabulous tool, IMO it still lacks the free software flavour that open knowledge should have. We as engineers should strive to be able to analyse a system in its entirety. In this sense, Scilab is a great alternative (I already used it with great success for my Master's Thesis). By integrating Scilab into the academic life, students are enabled to gain a deeper knowledge of the system they are to work with, they are freed from the cost of any proprietary tool and thus they are dissuaded from the infringement of the law (let's face reality). Moreover, Scilab enables them working from home as it can be freely installed on any computer. So, there is no longer the need to come to the laboratories of the university, a fact that is most practical for online students. To this end, this academic year I'll be working with Dr. Xavier Sevillano to accomplish the platform migration for the practice assignments of Discrete-Time Signal Processing. To date, I have enabled a "teaching" tab in my homepage to host a tutorial of Scilab, and some theory materials (coming soon). Post 37 FALA 2010 conference15-Sep-2010Good news. Our work on text classification of domain-styled text and sentiment-styled text for expressive speech synthesis has been selected for presentation at the FALA 2010 conference. The conference will be held on November at Vigo, Spain. In the context of text processing for Text-to-Speech (TTS) synthesis, we aim to automatically direct the expressiveness in speech through tagging the input text appropriately. Since the nature of text presents different characteristics according to whether it is domain-dependent (expressiveness related to its topics) or sentiment-dependent (expressiveness related to its sentiment), we study how these traits influence the identification of expressiveness in text, and develop a successful classification strategy. To this end, we consider two principal Text Classification (TC) methods, the Reduced Associative Relational Network and the Maximum Entropy classifier, and evaluate their performed effectiveness in domain/sentiment dependent environments. Additionally, we also evaluate how sensitive the classifiers are to the size of training data. The overall conclusions indicate that moving from a domain-dependent environment to a more general sentiment-dependent environment strictly results in poorer effectiveness rates, despite the sensible generalisation advantage that sentiment provides for dealing with expressiveness. There is also little influence on the size of the training data. Post 36 Donate your voice for the wealth of free speech recognition apps07-Sep-2010A week ago, the Fernando de los Rios Consortium, who maintains the Guadalinfo portal, launched the Donate your voice competition with the aim of compiling a voice corpus to produce a free acoustic model. This free acoustic model would then be used to develop a speech recognition application to control the desktop of a computer, similar to Magnus, but more professional :) This initiative was suggested by the Guadalinex development team with the aim to incorporate such a speech-enabled facility to the Gnome desktop of their GNU/Linux distribution. If there is no last-minute change, this voice desktop control app will use Julius as the core speech recognition engine, and Gnome-Voice-Control to glue Julius to Gnome. Post 35 Sentiment analysis with NLTK13-Aug-2010By the beginning of the month, Streamhacker set a demo of sentiment analysis using the Natural Language Toolkit NLTK, a powerful Python set of open source modules for research and development in natural language processing and text analytics. It is interesting to compare its features with EmoLib and see how different technologies tackle the same problem. For instance, Streamhacker's system is trained on movie reviews, identifying positive and negative sentiment, while EmoLib is trained on news headlines providing positive, negative and neutral sentiment tags, given the need of the neutral state in speech synthesis oriented applications. Regarding their innards, Streamhacker's system accounts for high-information words and collocations to train a Naive Bayes classifier and a Maximum Entropy classifier, while EmoLib represents the emotional words of a given text in a circumplex (a dimensional space of emotion) and yields a sentiment label according to a nearest centroid criterion (to the sentiment categories). Overall, the two systems work similarly. A deeper performance analysis would be necessary to extract further conclusions. Nevertheless, IMO and according to the results I obtained for my dissertation, the systems working directly with textual features are expected to perform better than the systems working with emotion dimensions, at the expense of their somewhat poorer generalisation capabilities (they are bound to their training text domains, therefore the interest in using a more general method like emotion dimensions). In this sense, regarding the datasets I used for the experiments, MaxEnt methods and Vector Space Model approaches performed the best. newer | older - RSS - Search |
All contents © Alexandre Trilla 2008-2025 |