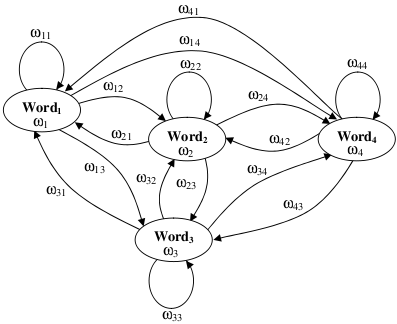
Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 53 Natural Language Generator (NLG) released01-Nov-2011I recall the tutorial that Noah Smith gave at LxMLS about Sequence Models with much interest. Motivated and inspired by his explanation, today I release a Natural Language Generator (NLG) based on n-gram Language Models (see the CODE section). Under the generative modelling paradigm, the history-based model P(w_n|w_1,w_2,...,w_{n-1}) (see further analysis in the NLG docs) may be graphically represented by a finite-state machine/automaton such as the Co-Occurrence Network (Mihalcea and Radev, 2011) that appears in Alias, et al. (2008), see the figure below. I find it self explanatory (a picture is worth a thousand words; it's funny to put it this way from a language processing perspective). Although it is limited by its first-order history (the NLG rather generalises its topology), the tutorial did not show such a clear representation of the model.
 I especially enjoyed the complexity issues that were raised regarding the length of the considered history (i.e., the order of the Markov model): from the Bag-Of-Words (BOW) model with few parameters and strong independence assumptions to the infinite-history-based model with a rich expressive power to represent language. Prof. Smith conducted an example experiment where he used a corpus of 2.8M words of American political blog text to display how this expressive power can learn and generate natural language. First, he showed how a unigram model (i.e., a BOW) could not produce anything that made any sense. Second, he showed how a bigram model could only produce a few phrases with sense. The experiment went on up to a 100-gram language model, which just copied text straight from training instances. Imagine how the aforementioned graphical network would look like in these scenarios, from a fully connected network of words (i.e., unigrams) to a mesh of higher order grams. He ended up discussing that in the past few years, "webscale" n-gram models have become very popular because it's very hard to beat them. In this post I reproduce the experiment with the NLG using "The Legend Of Sleepy Hollow", by Washington Irving, thanks to the e-book provided by Project Gutenberg (I could not find a more appropriate book after Halloween). What follows are some of the generated outputs:
Unigram model
Bigram model
Trigram model
5-gram model As it can be observed, as the model gains expressive power by means of its increased order, it can generate more quality natural language instances. Finally, as it is customary, the source code organisation of the NLG follows common FLOSS directives (such as src folder, doc, README, HACKING, COPYING, etc.). It only depends externally on the Boost Iostreams Library for tokenising text, and it makes use of the premake build script generation tool. I hope you enjoy it.
-- |
All contents © Alexandre Trilla 2008-2025 |