Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 61 Support Vector Machines and the importance of regularisation to approach the optimal boundary27-Nov-2011In this post I would like to show some empirical evidence about the importance of model regularisation in order to control the complexity so as to not overfit the data and generalise better. To this end, I make use of this week's work on Support Vector Machines (SVM) in the Machine Learning class. Firstly, a scenario similar to Post 52 is settled. Then, the optimal Bayes boundary is drawn, along with an unregularised SVM (C=100). Up to this point, the performance of this classifier is expected to be as modest as the former unregularised Logistic Regression: since it is tightly dependent on the observed samples, the slope of the linear boundary differs a lot from the optimum. Instead, when a considerable amount of regularisation is applied, i.e., a SVM with C=1, the model is more conservative and reticent to classify outliers, so its final slope approaches the optimum, thus increasing its expected effectiveness.
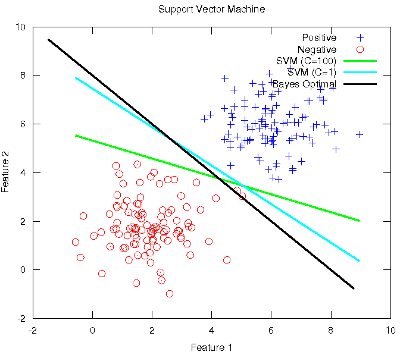 The Octave code used to generate the figure is available here. Note that the rest of the ml-class files need to be present along with the former. |
All contents © Alexandre Trilla 2008-2025 |