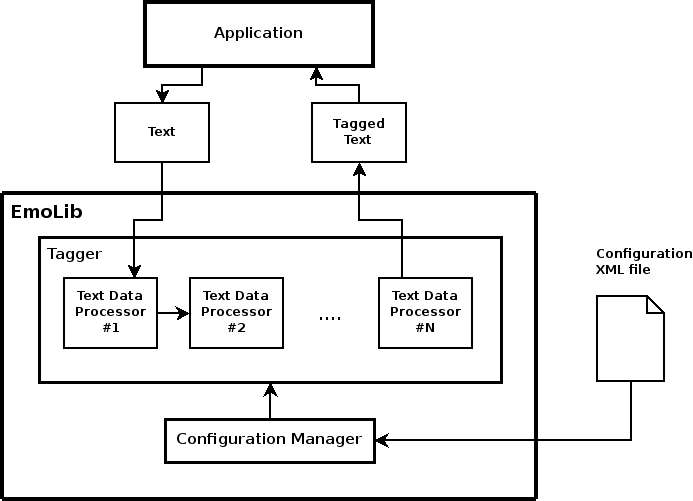
Figure 1: Architecture diagram of EmoLib.
|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||
See:
Description
| Packages | |
|---|---|
| emolib | Provides the highest level of abstraction of EmoLib: the text processing pipeline. |
| emolib.classifier | Provides a high-level class to perform the classification (categorisation) process. |
| emolib.classifier.eval | Provides classes implementing different classifier evaluation strategies to measure the effectiveness rates of the classifiers. |
| emolib.classifier.heuristic | Heuristic classifiers. |
| emolib.classifier.machinelearning | Machine Learning classifiers. |
| emolib.classifier.machinelearning.density | Provides some class-conditional densities for modeling the feature space. |
| emolib.eks | Provides a high-level class to perform the Emotional Keyword Spotting (EKS) process. |
| emolib.eks.anlw | Provides a class to perform the Emotional Keyword Spotting (EKS) using an Affective Norms Language Words (ANLW) dictionary. |
| emolib.formatter | Provides a high-level class to perform the formatting of the results. |
| emolib.formatter.xml | Provides a class to perform the formatting of the results process using an Extensible Markup Language (XML) specification. |
| emolib.pos | Provides a high-level class to perform the Part-Of-Speech tagging process. |
| emolib.pos.qtag | Provides a class to perform the Part-Of-Speech tagging process using the QTag POS tagger. |
| emolib.pos.stanford | Provides a class to perform the Part-Of-Speech tagging process using the Stanford POS tagger. |
| emolib.splitter | Provides a high-level class to perform the sentence segmentation process. |
| emolib.splitter.bdt | Provides a class to perform the sentence splitting through a hand-crafted Binary Decision Tree (BDT). |
| emolib.statistic | Provides a high-level class to calculate the emotional (dimensional) statistics. |
| emolib.statistic.average | Provides classes to perform the statistical calculations with the emotional data. |
| emolib.stemmer | Provides a high-level class to perform the stemming process. |
| emolib.stemmer.snowball | Provides a class to perform the stemming process using the Snowball Spanish stemming algorithm. |
| emolib.stemmer.snowball.ext | Provides classes to perform the stemming process using the Snowball stemming algorithms in different languages. |
| emolib.tokenizer | Provides a high-level class to perform the tokenisation process. |
| emolib.tokenizer.lexer.english | Provides classes to perform the tokenisation process in English using a JavaCC lexer. |
| emolib.tokenizer.lexer.spanish | Provides classes to perform the tokenisation process in Spanish using a JavaCC lexer. |
| emolib.util | Provides a set of configuration, processing, formatting and evaluation utilities for EmoLib. |
| emolib.util.conf | Provides a mechanism for managing persistent configuration data. |
| emolib.util.eval | Provides classes to evaluate the performance of EmoLib. |
| emolib.util.eval.semeval | Provides classes to evaluate the performance of EmoLib with the Semeval 2007 task dataset. |
| emolib.util.printer | Provides a class to test the contents of the processing pipeline. |
| emolib.util.proc | Provides high-level structural implementations of the tools to perform the text processing tasks. |
| emolib.util.servlet.en | Processing service in English. |
| emolib.util.servlet.es | Processing service in Spanish. |
| emolib.wsd | Provides a high-level class to perform the Word Sense Disambiguation process. |
| emolib.wsd.openthes | Provides a class to perform the Word Sense Disambiguation (WSD) process using the OpenThesaurus-es Spanish thesaurus. |
| emolib.wsd.simlib | Provides a high-level class to perform the word sense disambiguation (WSD) process using the WordNet Similarity library. |
EmoLib is a library that extracts the affect from text and tags it according to the feeling that is written or being conveyed.
The diagram below shows the general architecture of EmoLib:
The processing structure of EmoLib is built of several primary abstract classes that define a sequential modular framework, i.e., a pipeline, due to the dependencies in the tagging process. This pipeline is described in detail in the AffectiveTagger.
The actual (concrete) classes that perform the Natural Language Processing (NLP) tasks (identified in Figure 1 inside the Tagger block) inherit the common language-processing-wise methods and functions defined by these parent (abstract) classes. By following this specification, the system gains an additional degree of flexibility, scalability and maintainability. This responds to the need of obtaining a complete modular configurable framework for EmoLib.
The primary abstract classes that define the architecture of EmoLib are described as follows:
There's also an external monitor, i.e., the Printer, to help show the information (data) that flows in the processing pipeline in order to check that the different modules that build the chain work correctly.
The configuration issues are conducted by the Configuration Manager, which receives the specific configuration from an external XML config file. This system has been taken from the Sphinx-4 speech recognition project, so please refer to the pertinent documentation on the configuration specifications at the Configuration Management for Sphinx-4.
It is believed that the availability of a simple code is the best possible documentation in order to begin using EmoLib. See EmoLib Simple Example for further details.
|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||